// 启动 informer 监听 go c.PodInformer.Informer().Run(stopCh) c.InformerFactory.Start(stopCh)
// Wait for all caches to sync before scheduling. c.InformerFactory.WaitForCacheSync(stopCh) controller.WaitForCacheSync("scheduler", stopCh, c.PodInformer.Informer().HasSynced)
// Prepare a reusable run function. run := func(ctx context.Context) { sched.Run() // 主入口 <-ctx.Done() } // ... run(ctx) return fmt.Errorf("finished without leader elect") }
k8s.io/kubernetes/pkg/scheduler/scheduler.go
1 2 3 4 5 6 7 8 9
// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately. func(sched *Scheduler)Run() { if !sched.config.WaitForCacheSync() { return }
// 主入口函数 scheduleOne go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything) }
// Set up leader election if enabled. var leaderElectionConfig *leaderelection.LeaderElectionConfig if c.ComponentConfig.LeaderElection.LeaderElect { leaderElectionConfig, err = makeLeaderElectionConfig(c.ComponentConfig.LeaderElection, leaderElectionClient, recorder) }
type completedConfig struct { *Config } // CompletedConfig same as Config, just to swap private object. type CompletedConfig struct { // Embed a private pointer that cannot be instantiated outside of this package. // 嵌入一个私有的指针,避免在包外初始化 *completedConfig }
// Config has all the context to run a Scheduler type Config struct { // config is the scheduler server's configuration object. ComponentConfig kubeschedulerconfig.KubeSchedulerConfiguration // 认证相关的 Authentication apiserver.AuthenticationInfo Authorization apiserver.AuthorizationInfo Client clientset.Interface // k8s client InformerFactory informers.SharedInformerFactory // infromer factory PodInformer coreinformers.PodInformer // pod informer EventClient v1core.EventsGetter Recorder record.EventRecorder Broadcaster record.EventBroadcaster // LeaderElection is optional. LeaderElection *leaderelection.LeaderElectionConfig }
// KubeSchedulerConfiguration configures a scheduler type KubeSchedulerConfiguration struct { metav1.TypeMeta
// SchedulerName is name of the scheduler, used to select which pods // will be processed by this scheduler, based on pod's "spec.SchedulerName". // 调度器的名字,用于用户选择不同的调度器 SchedulerName string // AlgorithmSource specifies the scheduler algorithm source. // 指定算法的来源 AlgorithmSource SchedulerAlgorithmSource // RequiredDuringScheduling affinity is not symmetric, but there is an implicit PreferredDuringScheduling affinity rule // corresponding to every RequiredDuringScheduling affinity rule. // HardPodAffinitySymmetricWeight represents the weight of implicit PreferredDuringScheduling affinity rule, in the range 0-100. HardPodAffinitySymmetricWeight int32
// LeaderElection defines the configuration of leader election client. LeaderElection KubeSchedulerLeaderElectionConfiguration
// ClientConnection specifies the kubeconfig file and client connection // settings for the proxy server to use when communicating with the apiserver. ClientConnection apimachineryconfig.ClientConnectionConfiguration // HealthzBindAddress is the IP address and port for the health check server to serve on, // defaulting to 0.0.0.0:10251 HealthzBindAddress string // MetricsBindAddress is the IP address and port for the metrics server to // serve on, defaulting to 0.0.0.0:10251. MetricsBindAddress string
// DisablePreemption disables the pod preemption feature. // 是否禁止强制调度 DisablePreemption bool
// Complete fills in any fields not set that are required to have valid data. It's mutating the receiver. func(c *Config)Complete()CompletedConfig { cc := completedConfig{c}
if c.InsecureServing != nil { c.InsecureServing.Name = "healthz" } if c.InsecureMetricsServing != nil { c.InsecureMetricsServing.Name = "metrics" }
return CompletedConfig{&cc} }
配置初始化-之 scheduler.Config
切换整体,回到 Run 函数的初始化函数 schedulerConfig, err := NewSchedulerConfig(c)
// NewSchedulerConfig creates the scheduler configuration. funcNewSchedulerConfig(s schedulerserverconfig.CompletedConfig)(*scheduler.Config, error) {
// Set up the configurator which can create schedulers from configs. // 创建 configurator,用于生成各种需要的 config // 返回 configFactory, 文件定义在 k8s.io/kubernetes/pkg/scheduler/factory/factory.go // NewConfigFactory() -> 初始化各种 informer,比较重要的是 PodInformer // unscheduled pod queue /* args.PodInformer.Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{}) bool { // 用于过滤 pod.Spec.NodeName 为空等条件 Pod switch t := obj.(type) { case *v1.Pod: return unassignedNonTerminatedPod(t) && responsibleForPod(t, args.SchedulerName) case cache.DeletedFinalStateUnknown: if pod, ok := t.Obj.(*v1.Pod); ok { return unassignedNonTerminatedPod(pod) && responsibleForPod(pod, args.SchedulerName) } runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c)) return false default: runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj)) return false } }, Handler: cache.ResourceEventHandlerFuncs{ AddFunc: c.addPodToSchedulingQueue, UpdateFunc: c.updatePodInSchedulingQueue, DeleteFunc: c.deletePodFromSchedulingQueue, }, }, ) */ configurator := factory.NewConfigFactory(&factory.ConfigFactoryArgs{ SchedulerName: s.ComponentConfig.SchedulerName, Client: s.Client, NodeInformer: s.InformerFactory.Core().V1().Nodes(), PodInformer: s.PodInformer, PvInformer: s.InformerFactory.Core().V1().PersistentVolumes(), PvcInformer: s.InformerFactory.Core().V1().PersistentVolumeClaims(), ReplicationControllerInformer: s.InformerFactory.Core().V1().ReplicationControllers(), ReplicaSetInformer: s.InformerFactory.Apps().V1().ReplicaSets(), StatefulSetInformer: s.InformerFactory.Apps().V1().StatefulSets(), ServiceInformer: s.InformerFactory.Core().V1().Services(), PdbInformer: s.InformerFactory.Policy().V1beta1().PodDisruptionBudgets(), StorageClassInformer: storageClassInformer, HardPodAffinitySymmetricWeight: s.ComponentConfig.HardPodAffinitySymmetricWeight, EnableEquivalenceClassCache: utilfeature.DefaultFeatureGate.Enabled(features.EnableEquivalenceClassCache), DisablePreemption: s.ComponentConfig.DisablePreemption, PercentageOfNodesToScore: s.ComponentConfig.PercentageOfNodesToScore, BindTimeoutSeconds: *s.ComponentConfig.BindTimeoutSeconds, })
// https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/ source := s.ComponentConfig.AlgorithmSource // KubeSchedulerConfiguration` var config *scheduler.Config switch { // 创建调度算法有两种方式 Provider 和 用户指定的 Ploicy 文件(文件或Configmap) // --algorithm-provider string // DEPRECATED: the scheduling algorithm provider to use, one of: // ClusterAutoscalerProvider | DefaultProvider case source.Provider != nil: // Create the config from a named algorithm provider. // 使用前面创建的 configurator 创建命名的算法 provider 配置 // ClusterAutoscalerProvider | DefaultProvider sc, err := configurator.CreateFromProvider(*source.Provider) config = sc // --policy-config-file string //DEPRECATED: file with scheduler policy configuration. This file is used if policy ConfigMap is not provided or --use-legacy-policy-config=true
case source.Policy != nil: // Create the config from a user specified policy source. policy := &schedulerapi.Policy{} switch { case source.Policy.File != nil: // Use a policy serialized in a file. policyFile := source.Policy.File.Path data, err := ioutil.ReadFile(policyFile) err = runtime.DecodeInto(latestschedulerapi.Codec, []byte(data), policy)
// 从 configmap 初始化 case source.Policy.ConfigMap != nil: // 处理流程同上 } sc, err := configurator.CreateFromConfig(*policy) config = sc default: returnnil, fmt.Errorf("unsupported algorithm source: %v", source) } // Additional tweaks to the config produced by the configurator. config.Recorder = s.Recorder
// Creates a scheduler from a set of registered fit predicate keys and priority keys. func(c *configFactory)CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender)(*scheduler.Config, error) { // ...
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting. func(sched *Scheduler)scheduleOne() { // 从队列中取出待调度的 Pod,最终调用的函数为 configFactory.getNextPod() pod := sched.config.NextPod() // 检查是否是被删除的,如果是则跳过 // Synchronously attempt to find a fit for the pod. start := time.Now() // 获取待调度 Pod 匹配的主机名 suggestedHost, err := sched.schedule(pod) // 见后续分析 if err != nil { // schedule() 可能因为没有满足调度的 Node 而失败,后续进行 preempt, if fitError, ok := err.(*core.FitError); ok { preemptionStartTime := time.Now() sched.preempt(pod, fitError) } return } // Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet. // This allows us to keep scheduling without waiting on binding to occur. assumedPod := pod.DeepCopy()
// 判断是否需要VolumeScheduling特性 // Assume volumes first before assuming the pod. If all volumes are completely bound, then allBound is true and binding will be skipped. Otherwise, binding of volumes is started after the pod is assumed, but before pod binding. This function modifies 'assumedPod' if volume binding is required. allBound, err := sched.assumeVolumes(assumedPod, suggestedHost) if err != nil { return }
// assume modifies `assumedPod` by setting NodeName=suggestedHost // Pod 对应的 NodeName 写上主机名,存入缓存 err = sched.assume(assumedPod, suggestedHost)
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above). // 请求apiserver,异步处理最终的绑定,写入到etcd gofunc() { // Bind volumes first before Pod if !allBound { err = sched.bindVolumes(assumedPod) }
// Schedule tries to schedule the given pod to one of the nodes in the node list. // If it succeeds, it will return the name of the node. // If it fails, it will return a FitError error with reasons. func(g *genericScheduler)Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister)(string, error) {
nodes, err := nodeLister.List()
// Used for all fit and priority funcs. err = g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
// Filters the nodes to find the ones that fit based on the given predicate functions // Each node is passed through the predicate functions to determine if it is a fit func(g *genericScheduler)findNodesThatFit(pod *v1.Pod, nodes []*v1.Node)([]*v1.Node, FailedPredicateMap, error) { var filtered []*v1.Node failedPredicateMap := FailedPredicateMap{}
// Stops searching for more nodes once the configured number of feasible nodes // are found. workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
// podFitsOnNode checks whether a node given by NodeInfo satisfies the given predicate functions. // For given pod, podFitsOnNode will check if any equivalent pod exists and try to reuse its cached // predicate results as possible. // This function is called from two different places: Schedule and Preempt. // When it is called from Schedule, we want to test whether the pod is schedulable // on the node with all the existing pods on the node plus higher and equal priority // pods nominated to run on the node. // When it is called from Preempt, we should remove the victims of preemption and // add the nominated pods. Removal of the victims is done by SelectVictimsOnNode(). // It removes victims from meta and NodeInfo before calling this function. funcpodFitsOnNode( pod *v1.Pod, meta algorithm.PredicateMetadata, info *schedulercache.NodeInfo, predicateFuncs map[string]algorithm.FitPredicate, cache schedulercache.Cache, nodeCache *equivalence.NodeCache, queue SchedulingQueue, alwaysCheckAllPredicates bool, equivClass *equivalence.Class, )(bool, []algorithm.PredicateFailureReason, error) { var ( eCacheAvailable bool failedPredicates []algorithm.PredicateFailureReason )
podsAdded := false // We run predicates twice in some cases. If the node has greater or equal priority // nominated pods, we run them when those pods are added to meta and nodeInfo. // If all predicates succeed in this pass, we run them again when these // nominated pods are not added. This second pass is necessary because some // predicates such as inter-pod affinity may not pass without the nominated pods. // If there are no nominated pods for the node or if the first run of the // predicates fail, we don't run the second pass. // We consider only equal or higher priority pods in the first pass, because // those are the current "pod" must yield to them and not take a space opened // for running them. It is ok if the current "pod" take resources freed for // lower priority pods. // Requiring that the new pod is schedulable in both circumstances ensures that // we are making a conservative decision: predicates like resources and inter-pod // anti-affinity are more likely to fail when the nominated pods are treated // as running, while predicates like pod affinity are more likely to fail when // the nominated pods are treated as not running. We can't just assume the // nominated pods are running because they are not running right now and in fact, // they may end up getting scheduled to a different node. for i := 0; i < 2; i++ { metaToUse := meta nodeInfoToUse := info // 第一次调度,根据NominatedPods更新meta和nodeInfo信息,pod根据更新后的信息去预选 // 第二次调度,meta和nodeInfo信息不变,保证pod不完全依赖于NominatedPods(主要考虑到pod亲和性之类的) if i == 0 { podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue) } elseif !podsAdded || len(failedPredicates) != 0 { break } // Bypass eCache if node has any nominated pods. // TODO(bsalamat): consider using eCache and adding proper eCache invalidations // when pods are nominated or their nominations change. eCacheAvailable = equivClass != nil && nodeCache != nil && !podsAdded for _, predicateKey := range predicates.Ordering() { var ( fit bool reasons []algorithm.PredicateFailureReason err error ) if predicate, exist := predicateFuncs[predicateKey]; exist { if eCacheAvailable { fit, reasons, err = nodeCache.RunPredicate(predicate, predicateKey, pod, metaToUse, nodeInfoToUse, equivClass, cache) } else { fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse) }
if !fit { // eCache is available and valid, and predicates result is unfit, record the fail reasons failedPredicates = append(failedPredicates, reasons...) // if alwaysCheckAllPredicates is false, short circuit all predicates when one predicate fails.
// PrioritizeNodes prioritizes the nodes by running the individual priority functions in parallel. // Each priority function is expected to set a score of 0-10 // 0 is the lowest priority score (least preferred node) and 10 is the highest // Each priority function can also have its own weight // The node scores returned by the priority function are multiplied by the weights to get weighted scores // All scores are finally combined (added) to get the total weighted scores of all nodes funcPrioritizeNodes( pod *v1.Pod, nodeNameToInfo map[string]*schedulercache.NodeInfo, meta interface{}, priorityConfigs []algorithm.PriorityConfig, nodes []*v1.Node, extenders []algorithm.SchedulerExtender, )(schedulerapi.HostPriorityList, error) { // If no priority configs are provided, then the EqualPriority function is applied // This is required to generate the priority list in the required format iflen(priorityConfigs) == 0 && len(extenders) == 0 { result := make(schedulerapi.HostPriorityList, 0, len(nodes)) for i := range nodes { hostPriority, err := EqualPriorityMap(pod, meta, nodeNameToInfo[nodes[i].Name]) if err != nil { returnnil, err } result = append(result, hostPriority) } return result, nil }
var ( mu = sync.Mutex{} wg = sync.WaitGroup{} errs []error )
for i, priorityConfig := range priorityConfigs { if priorityConfig.Function != nil { wg.Add(1) gofunc(index int, config algorithm.PriorityConfig) { defer wg.Done() var err error results[index], err = config.Function(pod, nodeNameToInfo, nodes) if err != nil { appendError(err) } }(i, priorityConfig) } else { results[i] = make(schedulerapi.HostPriorityList, len(nodes)) } }
processNode := func(index int) { nodeInfo := nodeNameToInfo[nodes[index].Name] var err error for i := range priorityConfigs { // 使用 map 函数计算过程数据 results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo) } } workqueue.Parallelize(16, len(nodes), processNode) for i, priorityConfig := range priorityConfigs { wg.Add(1) gofunc(index int, config algorithm.PriorityConfig) { // 使用 reduce 函数结算结果 if err := config.Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil { appendError(err) } }(i, priorityConfig) } // Wait for all computations to be finished. wg.Wait() // Summarize all scores. result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes { result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0}) for j := range priorityConfigs { result[i].Score += results[j][i].Score * priorityConfigs[j].Weight } }
// 继续使用 extenders 来进行优选 iflen(extenders) != 0 && nodes != nil { combinedScores := make(map[string]int, len(nodeNameToInfo)) for _, extender := range extenders { wg.Add(1) gofunc(ext algorithm.SchedulerExtender) { defer wg.Done() prioritizedList, weight, err := ext.Prioritize(pod, nodes) if err != nil { // Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities return } mu.Lock() for i := range *prioritizedList { host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score combinedScores[host] += score * weight } mu.Unlock() }(extender) } // wait for all go routines to finish wg.Wait() for i := range result { result[i].Score += combinedScores[result[i].Host] } } return result, nil }
// IMPORTANT NOTES for predicate developers: // We are using cached predicate result for pods belonging to the same equivalence class. // So when implementing a new predicate, you are expected to check whether the result // of your predicate function can be affected by related API object change (ADD/DELETE/UPDATE). // If yes, you are expected to invalidate the cached predicate result for related API object change. // For example: // https://github.com/kubernetes/kubernetes/blob/36a218e/plugin/pkg/scheduler/factory/factory.go#L422
// Registers predicates and priorities that are not enabled by default, but user can pick when creating their // own set of priorities/predicates.
// PodFitsPorts has been replaced by PodFitsHostPorts for better user understanding. // For backwards compatibility with 1.0, PodFitsPorts is registered as well. factory.RegisterFitPredicate("PodFitsPorts", predicates.PodFitsHostPorts) // Fit is defined based on the absence of port conflicts. // This predicate is actually a default predicate, because it is invoked from // predicates.GeneralPredicates() factory.RegisterFitPredicate(predicates.PodFitsHostPortsPred, predicates.PodFitsHostPorts) // Fit is determined by resource availability. // This predicate is actually a default predicate, because it is invoked from // predicates.GeneralPredicates() factory.RegisterFitPredicate(predicates.PodFitsResourcesPred, predicates.PodFitsResources) // Fit is determined by the presence of the Host parameter and a string match // This predicate is actually a default predicate, because it is invoked from // predicates.GeneralPredicates() factory.RegisterFitPredicate(predicates.HostNamePred, predicates.PodFitsHost) // Fit is determined by node selector query. factory.RegisterFitPredicate(predicates.MatchNodeSelectorPred, predicates.PodMatchNodeSelector)
// ServiceSpreadingPriority is a priority config factory that spreads pods by minimizing // the number of pods (belonging to the same service) on the same node. // Register the factory so that it's available, but do not include it as part of the default priorities // Largely replaced by "SelectorSpreadPriority", but registered for backward compatibility with 1.0 factory.RegisterPriorityConfigFactory( "ServiceSpreadingPriority", factory.PriorityConfigFactory{ MapReduceFunction: func(args factory.PluginFactoryArgs)(algorithm.PriorityMapFunction, algorithm.PriorityReduceFunction) { return priorities.NewSelectorSpreadPriority(args.ServiceLister, algorithm.EmptyControllerLister{}, algorithm.EmptyReplicaSetLister{}, algorithm.EmptyStatefulSetLister{}) }, Weight: 1, }, ) // EqualPriority is a prioritizer function that gives an equal weight of one to all nodes // Register the priority function so that its available // but do not include it as part of the default priorities factory.RegisterPriorityFunction2("EqualPriority", core.EqualPriorityMap, nil, 1) // Optional, cluster-autoscaler friendly priority function - give used nodes higher priority. factory.RegisterPriorityFunction2("MostRequestedPriority", priorities.MostRequestedPriorityMap, nil, 1) factory.RegisterPriorityFunction2( "RequestedToCapacityRatioPriority", priorities.RequestedToCapacityRatioResourceAllocationPriorityDefault().PriorityMap, nil, 1) }
// IMPORTANT NOTE: this list contains the ordering of the predicates, if you develop a new predicate // it is mandatory to add its name to this list. // Otherwise it won't be processed, see generic_scheduler#podFitsOnNode(). // The order is based on the restrictiveness & complexity of predicates. // Design doc: https://github.com/kubernetes/community/blob/master/contributors/design-proposals/scheduling/predicates-ordering.md
funcdefaultPredicates()sets.String { return sets.NewString( // ... // Fit is determined by node conditions: not ready, // network unavailable or out of disk. factory.RegisterMandatoryFitPredicate(predicates.CheckNodeConditionPred, predicates.CheckNodeConditionPredicate), // 见下文函数分析 // ... }
// CheckNodeConditionPredicate checks if a pod can be scheduled on a node reporting out of disk, // network unavailable and not ready condition. Only node conditions are accounted in this predicate. funcCheckNodeConditionPredicate(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo)(bool, []algorithm.PredicateFailureReason, error) { reasons := []algorithm.PredicateFailureReason{}
// RegisterFitPredicate registers a fit predicate with the algorithm // registry. Returns the name with which the predicate was registered. funcRegisterFitPredicate(name string, predicate algorithm.FitPredicate)string { return RegisterFitPredicateFactory(name, func(PluginFactoryArgs)algorithm.FitPredicate { return predicate }) }
funcdefaultPriorities()sets.String { return sets.NewString( // spreads pods by minimizing the number of pods (belonging to the same service or replication controller) on the same node. factory.RegisterPriorityConfigFactory( "SelectorSpreadPriority", factory.PriorityConfigFactory{ MapReduceFunction: func(args factory.PluginFactoryArgs)(algorithm.PriorityMapFunction, algorithm.PriorityReduceFunction) { return priorities.NewSelectorSpreadPriority(args.ServiceLister, args.ControllerLister, args.ReplicaSetLister, args.StatefulSetLister) }, Weight: 1, }, ), // pods should be placed in the same topological domain (e.g. same node, same rack, same zone, same power domain, etc.) // as some other pods, or, conversely, should not be placed in the same topological domain as some other pods. factory.RegisterPriorityConfigFactory( "InterPodAffinityPriority", factory.PriorityConfigFactory{ Function: func(args factory.PluginFactoryArgs)algorithm.PriorityFunction { return priorities.NewInterPodAffinityPriority(args.NodeInfo, args.NodeLister, args.PodLister, args.HardPodAffinitySymmetricWeight) }, Weight: 1, }, ),
// Prioritize nodes by least requested utilization. factory.RegisterPriorityFunction2("LeastRequestedPriority", priorities.LeastRequestedPriorityMap, nil, 1),
// Prioritizes nodes to help achieve balanced resource usage factory.RegisterPriorityFunction2("BalancedResourceAllocation", priorities.BalancedResourceAllocationMap, nil, 1),
// Set this weight large enough to override all other priority functions. // TODO: Figure out a better way to do this, maybe at same time as fixing #24720. factory.RegisterPriorityFunction2("NodePreferAvoidPodsPriority", priorities.CalculateNodePreferAvoidPodsPriorityMap, nil, 10000),
// Prioritizes nodes that have labels matching NodeAffinity factory.RegisterPriorityFunction2("NodeAffinityPriority", priorities.CalculateNodeAffinityPriorityMap, priorities.CalculateNodeAffinityPriorityReduce, 1),
// Prioritizes nodes that marked with taint which pod can tolerate. factory.RegisterPriorityFunction2("TaintTolerationPriority", priorities.ComputeTaintTolerationPriorityMap, priorities.ComputeTaintTolerationPriorityReduce, 1),
// ImageLocalityPriority prioritizes nodes that have images requested by the pod present. factory.RegisterPriorityFunction2("ImageLocalityPriority", priorities.ImageLocalityPriorityMap, nil, 1), ) }

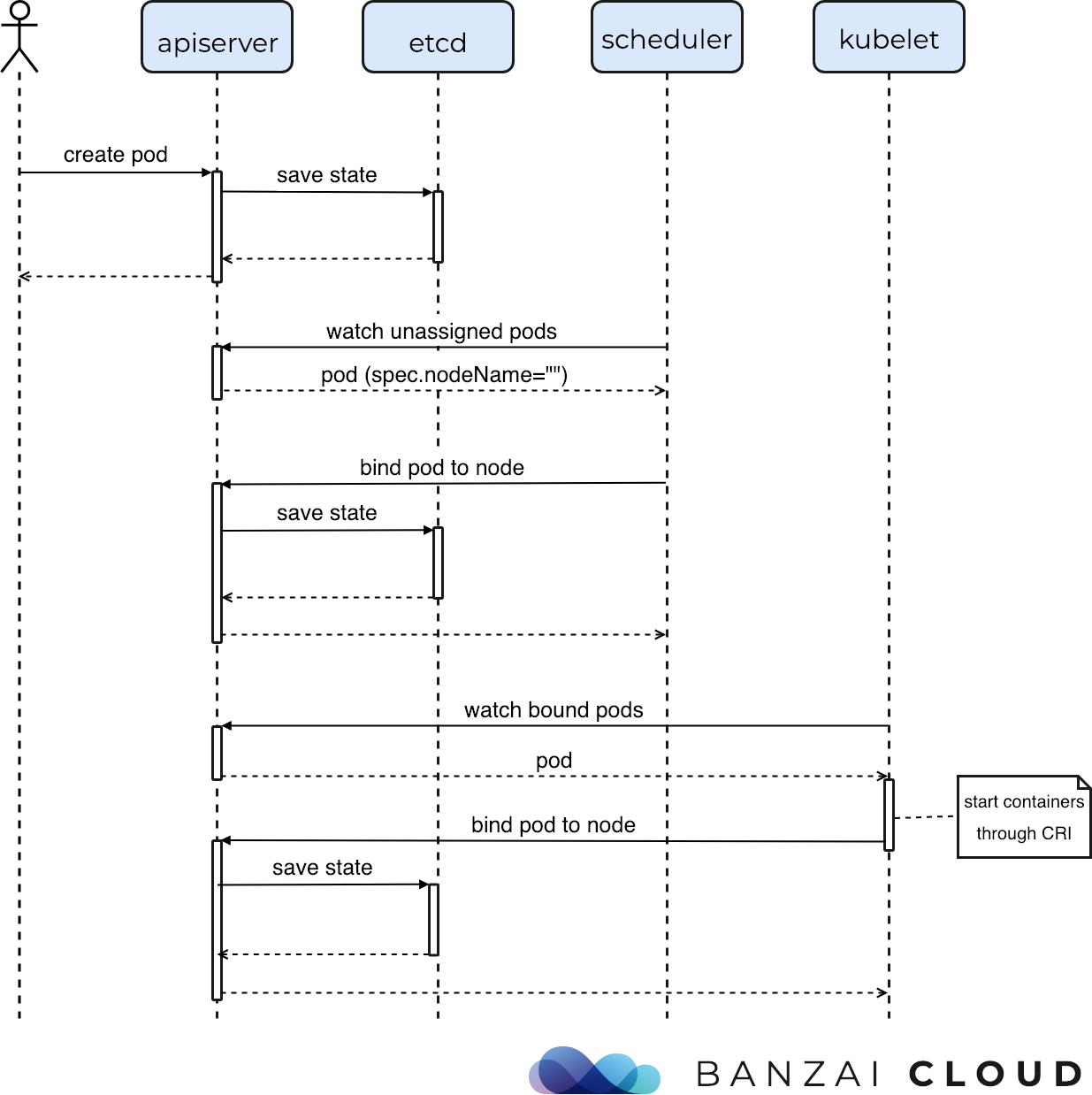
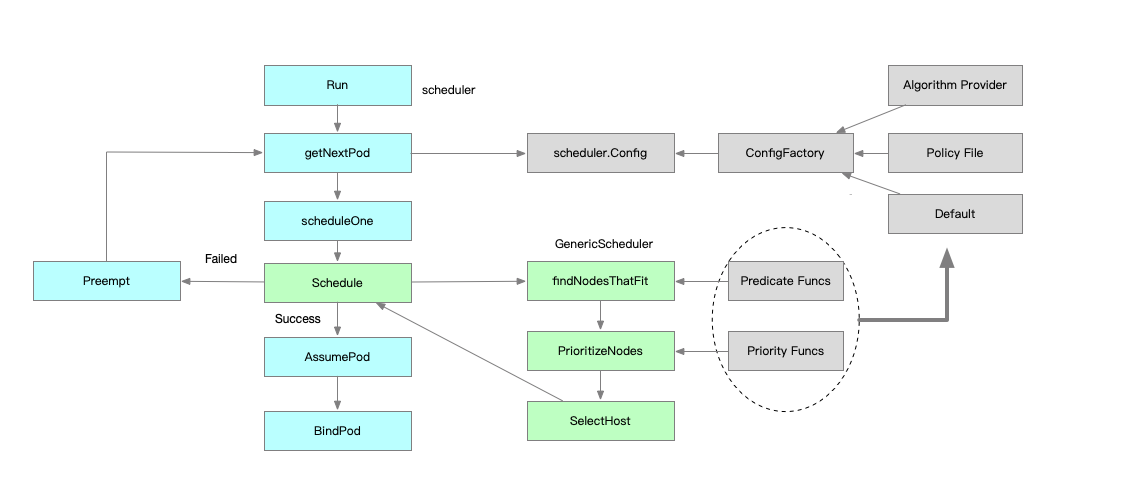
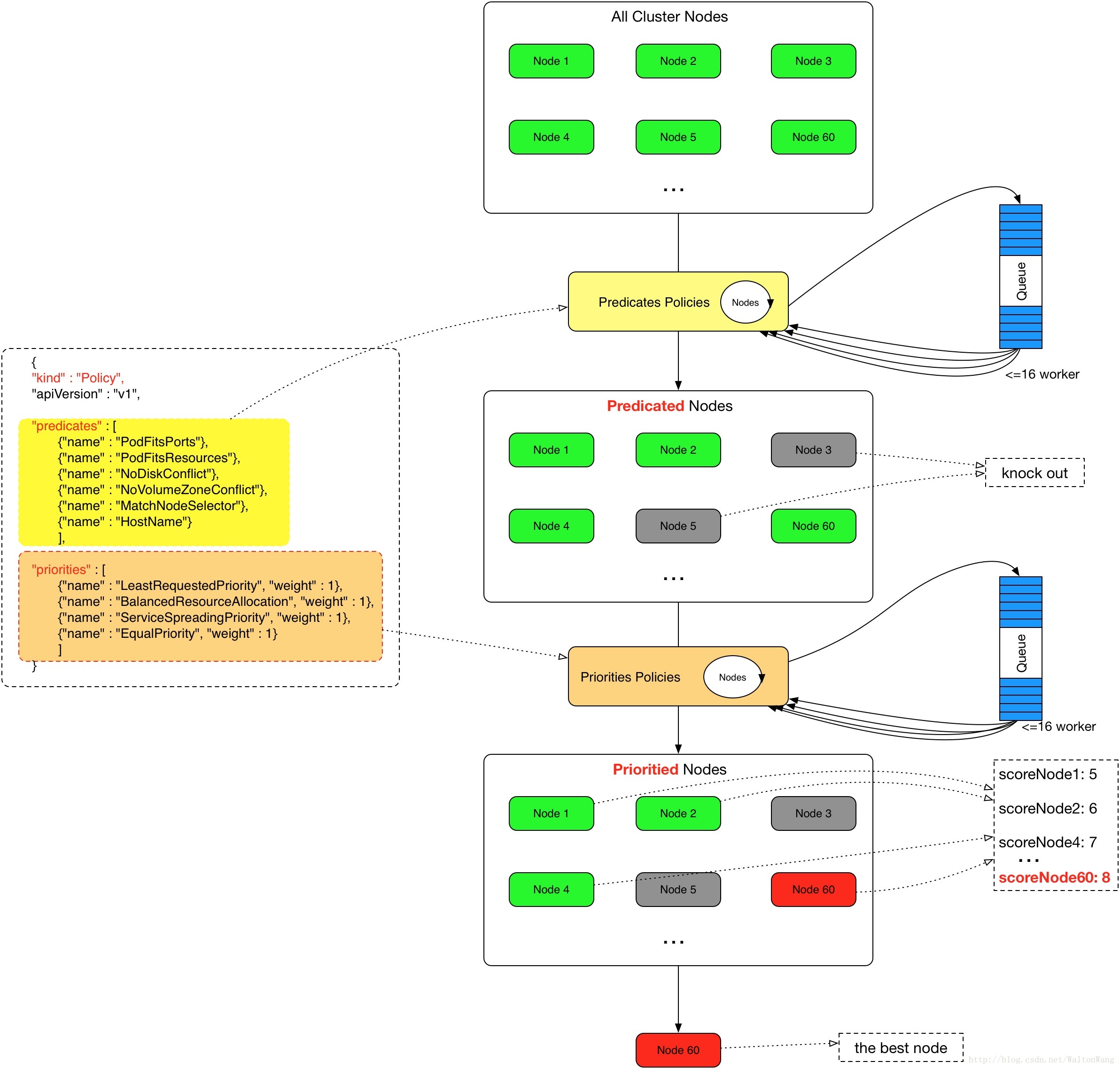 来源https://ggaaooppeenngg.github.io/zh-CN/2017/09/26/kubernetes-%E6%8C%87%E5%8C%97/Schedule.jpeg
来源https://ggaaooppeenngg.github.io/zh-CN/2017/09/26/kubernetes-%E6%8C%87%E5%8C%97/Schedule.jpeg